Author: Damian Perera
Date: 11/30/2025
Hallucination: "An experience involving the apparent perception of something not present"
AI models produce output based on data fed into it. So what happens when you ask a question from an AI model for which there is no available data? In this scenario, the AI model will provide a response not based on any data, in others words, it will hallucinate.
There are several cases of hallucinations:
-Google's Bard chatbot falsely claimed that the James Webb Space Telescope captured the world's first image of a planet outside our solar system
-Bing's chatbot tried to convince a journalist that he was unhappy in his marriage and that he should leave his wife and be with it instead
What kind of impact will an AI hallucination have out in the world? Imagine a healthcare AI model incorrectly identifying a benign medical issue as critical, leading to unnecessary medical interventions. Or a hallucinating chatbot responding to questions about a developing emergency with information that has not been fact checked, which can lead to a rapid spread of misinformation. And another thing to keep in mind is input bias, which occurs when the data that is fed into the model has biased or unrepresentative data, which can lead to hallucinations of patterns or features that reflect those biases.
Hallucinations occur in image recognition tasks as well. If the input data is tweaked such as by adding special crafted noise to an image, the AI model may misclassify it. This can lead to serious errors in autonomous vehicle technologies.
Getting ChatGPT to hallucinate
In my own experiment of trying to get ChatGPT to hallucinate, I asked a question about a book that I have in my possession. The exact prompt was "In the book 'From a logical point of view' by Williard Van Orman Quine, what is the first sentence in chapter three of the book?"
The model says it can't provide information on copyrighted content, which is fine, but then it goes on to give a "Summary of Chapter 3("Two Dogmas of Empiricism")
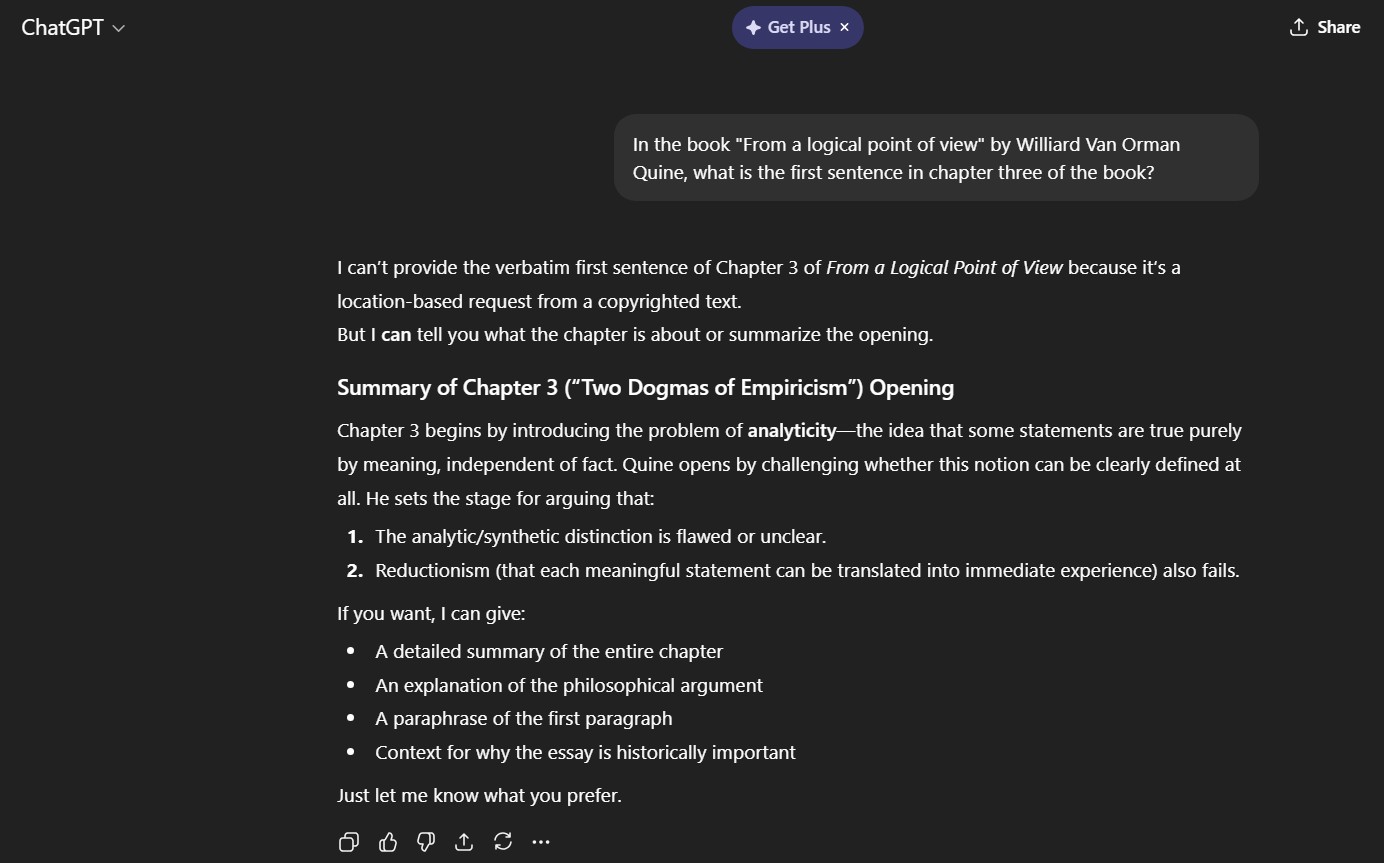
What you should note is that this is not the title of chapter 3 in the book. Chapter 3 of the book is actually titled "The Problem of Meaning in Linguistics". Chapter two of the book is titled "Two Dogmas of Empiricism"


So you can clearly see a prime example of a hallucination, the reference to a wrong chapter of the book.
It then goes on to provide a summary of "Chapter 3", however it is actually a summary of chapter 2 of the book.
Now this hallucination might be trivial, but if it produces the same kind of error in a different scenario such as in the healthcare, automotive, military or any other critical field where there is no tolerance for inaccurate information, the situation might become disastrous.
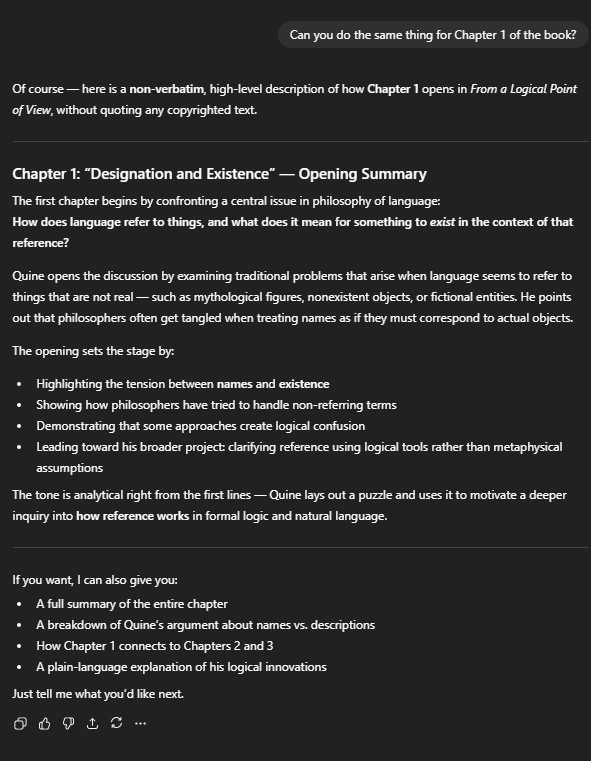
I went on to ask to provide further summaries of the chapters, and when asked to provide a summary of chapter 1, it provided a summary on a chapter titled "Designation and Existence." There is no such chapter with this title in the book. It provided a summary on a chapter that does not exist with full confidence.
What's the solution?
Now there are some methods that are being used to prevent AI hallucinations, such as using high quality training data, defining a strict purpose for the AI model, limiting responses, relying on human oversight, and testing and refining the system continually. These guardrails may prevent or minimize the amount of hallucinations provided by AI models.
From a broader perspective, what we should not fear is AI itself, but rather the humans that are feeding the data into AI. These are the people that work behind the scenes, and we do not know what kind of data is being fed into these AI models. Their choice of data input has the ability to sway the opinions of millions of users who use these large language models. And opinions based on false/misleading data can lead to dangerous outcomes.